Имплементиран пројекат Платформа за истраживање дигитализованог садржаја новинских колекција потпомогнута језичким технологијама за српски језик (ПИСАН)
Имплементиран пројекат Платформа за истраживање дигитализованог садржаја новинских колекција потпомогнута језичким технологијама за српски језик (ПИСАН)
Универзитетска библиотека „Светозар Марковић“ успешно је имплементирала пројекат
Платформа за истраживање дигитализованог садржаја новинских колекција
потпомогнута језичким технологијама за српски језик (ПИСАН). Пројекат је урађен у
оквиру Конкурса за финансирање или суфинансирање пројеката из области
дигитализације културног наслеђа у 2025. години МИНИСТАРСТВА КУЛТУРЕ
РЕПУБЛИКЕ СРБИЈЕ, а на основу РЕШЕЊА бр. 003903639 2025 11800 001 013 630 002
од 23.09.2025. године и Уговора бр. 451-04-1830/2025-02 од 07.10.2025.
Платформа за истраживање дигитализованог садржаја новинских колекција (ПИСАН)
потпомогнута језичким технологијама за српски језик представља иновативни систем
осмишљен за анализу и обраду великих корпуса новинских текстова. Главна идеја
произлази из потребе корисника да се културно наслеђе и богатство историјских часописа
на српском језику учине доступнијим за анализу и интерпретирање помоћу савремених
технологија обраде природног језика. Током спецификације корисничких потреба јасно је
указана потреба за поновним препознавањем карактера имајући у виду брз развој нових и
иновативних метода потпомогнутих великим језичким моделима које дају много боље
резултате. Приликом обраде текста ослонити се на општеприхваћене стандарде, у првом
реду TEI (Text Enciding Iniciative) и на најбоље моделе који тренутно постоје за српски
језик када је у питању обележавање именованих ентитета и њихово повезивање са базама
знања. Изабрати развојну платформу која ће омогућити публиковање, добру
визуелизацију и претраживање пуног текста, која је уз то погодна за дигиталне
хуманистичке пројекте, корпусе, дигитална издања и архиве.
Пројекат се ослањао на аутоматско рашчитавање (оптичко препознавање карактера) и
корекцију текста, потом трансформацију у TEI (Text Enciding Iniciative) документ са
структурним елементима (одељци, параграфи, реченице) за шта је креиран посебан
програм прилагођен потребама пројекта. Следећи корак био је препознавање ентитета и
кључних појмова, успостављање релација ка бази знања Википодаци
https://www.wikidata.org/ , као и повезивање са осталим базама знања путем реализоване
везе са Википодацима, чиме се омогућава брзо и ефикасно лоцирање, категоризација и
пружање богатијег контекста за значајне догађаје, личности и друштвене појаве
забележене у старим новинама. Истовремено, корисници ће имати више могућности на
располагању, а читава колекција ће имати повећану видљивост. Самим тим, биће повећана
и видљивост српске ћирилице, будући да су одабране новине из ћириличког корпуса.
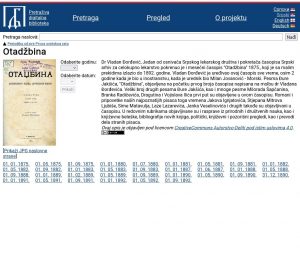
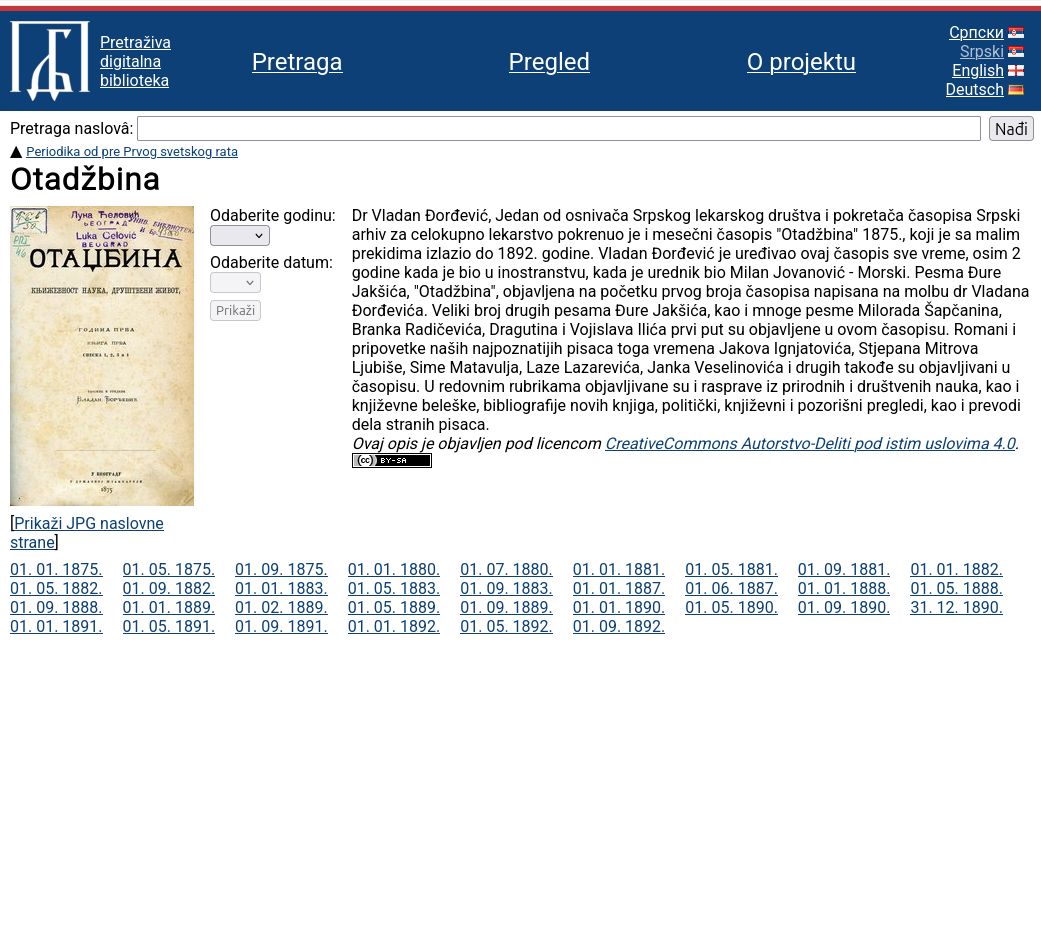
Конкретно, у оквиру пројекта су обрађени часописи: Отаџбина
(https://pretraziva.rs/pregled/otadzbina), Зора (https://pretraziva.rs/pregled/zora), Жена
(https://pretraziva.rs/pregled/zena) и Дело (https://pretraziva.rs/pregled/delo), како би се
илустровао пуни потенцијал платформе.
Због кратког рока за имплементацију пројекта, одређене сасвим техничке активности су
отпочеле раније. На пример, у оквиру пројекта ТЕСЛА – векторизација језика: апликације
за српски језик, који финансира Фонд за науку Републике Србије, развијају се напредни
језички ресурси и модели засновани на техникама машинског учења за српски језик (из
модела Word2Vec, FastText, BERT, GPT-2, XLMR, T5,…), чија је интеграција омогућила
боље препознавање семантичких веза између речи и прецизније издвајање кључних
ентитета у новинским текстовима. Интеграцијом тих ресурса са Претраживом и
платформом заснованом на алату TEI Publisher која је развијена у овом пројекту, добија се
јединствена прилика за унапређивање процеса повезивања архивских података, јер ће
векторске репрезентације и модели ТЕСЛА-e омогућити дубљу и детаљнију анализу
текста, идентификовање скривених односа и аутоматско груписање сродних појмова. На
тај начин, олакшава се проналажење смислених корелација, које су неопходне за
свеобухватно истраживање културног и историјског контекста, уз значајно смањење
ручног рада и унапређење прецизности у раду истраживача, библиотекара и других
корисника.
Главни циљ пројекта био је развој алата за истраживање дигитализованих садржаја
културне баштине у књижевним новинама на српском језику, уз примену савремених
језичких технологија, укључујући препознавање ентитета, кључних појмова, повезивање
са базама знања са успостављањем релација. Платформа са пратећим веб-сервисима је
замишљена да буде корисна за истраживаче, историчаре, библиотекаре и друге
заинтересоване за историју, културу, језик и језичке технологије. Захваљујући
унапређеним функционалностима, Платформа омогућава ефикасно и брзо проналажење и
екстракцију информација, као и њихову визуелизацију у виду графова знања, карата,
мрежа, временских дијаграма и слично.
Осим изградње платформе, у склопу пројекта су обрађена четири часописа из дигиталне
колекције ПРЕТРАЖИВА Универзитетске библиотеке „Светозар Марковић“.
Истовремено, повећана је видљивост ћирилице у дигиталном окружењу.
Пројекат је рађен у сарадњи са Друштвом за језичке ресурсе и технологије – ЈеРТех.